
Scalable System Architecture with Docker, Docker Flow, and Elastic Stack: Limitations and Final Thoughts
Final part of the Scalable Architecture series. Just limitations I encountered and thoughts

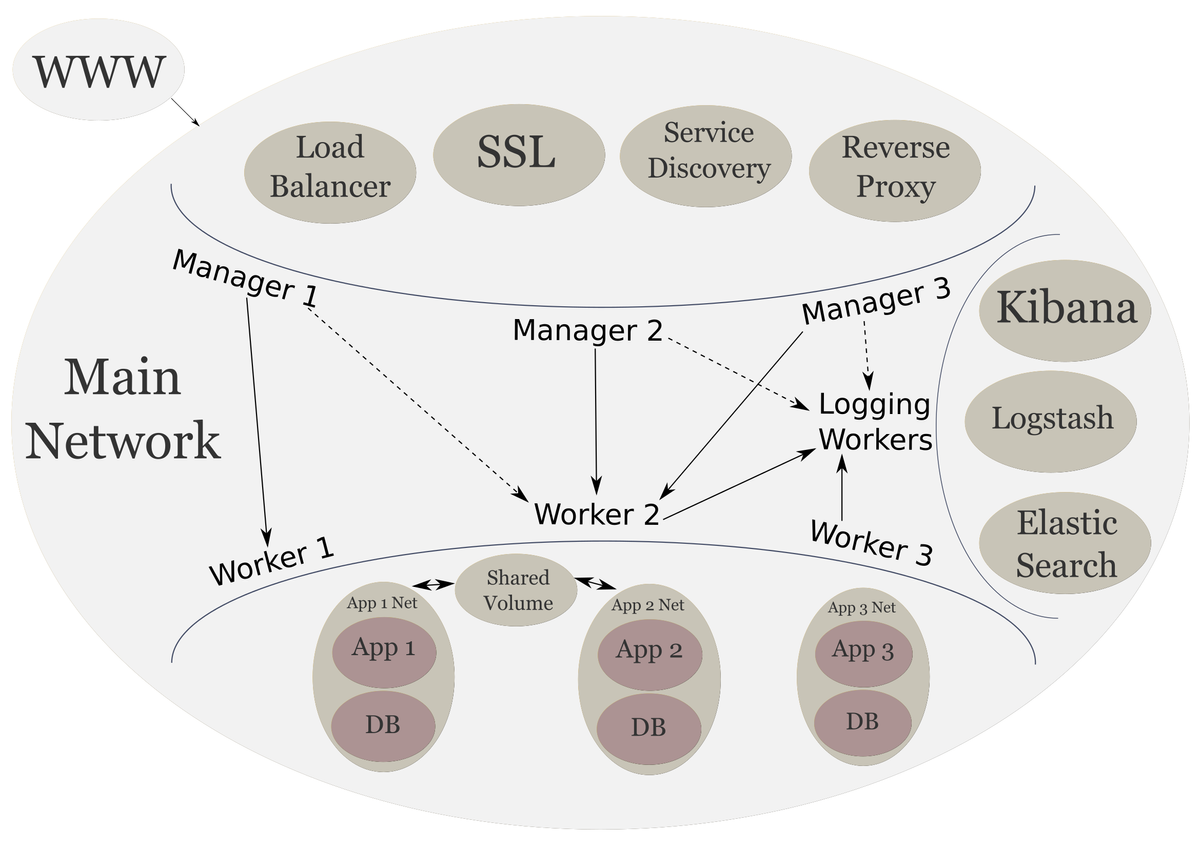
Scalable System Architecture
In the previous post, we completed our architecture by creating our backend services. Now I will just share some limitations I found while building up this architecture. Limitations that we should all keep in mind. And I will share my final thoughts on the learning experience and the architecture.
Parts
- Scalable System Architecture with Docker, Docker Flow, and Elastic Stack: System Provisioning
- Scalable System Architecture with Docker, Docker Flow, and Elastic Stack: Frontend Services
- Scalable System Architecture with Docker, Docker Flow, and Elastic Stack: Logging Stack
- Scalable System Architecture with Docker, Docker Flow, and Elastic Stack: Backend Services
- Scalable System Architecture with Docker, Docker Flow, and Elastic Stack: Limitations and Final Thoughts(current)
Limitations
When we are creating this architecture and using it in production, it is important to understand the limitations of the system. There are some limitations with Docker Swarm currently that we will look at. These limitations are by no means complete blockers of the system. They either have workarounds or will most likely be solved in future versions of Docker.
These are not all of the limitations of Docker and Swarm. These are just ones that I am aware of and have encountered while implementing this architecture.
Volumes
The limitation with volumes is duplication of those volumes from one swarm node to another. If a service is replicated on all of the workers then that volume will be created on all of the workers. But the data in those volumes will differ.
This volume fragmentation can be mitigated by using a networked file system. And using named volumes. The NFS storage drive should be mounted on the nodes that must have volumes, and the named volume's source must point to a folder on that mounted drive. Given the Docker daemon has write permission to the network drive, the folder will be created automatically when the service is create.
docker service create --name app --label com.df.notify=true --label com.df.distribute=true --label com.df.serviceDomain='customdomain.com' --label com.df.servicePath=/app1 --network main --mount type=volume,source=/path/to/network/drive,destination=/app/folder --replicas 3 app:latest
Swarm
The limitation with the swarm is that there is no built in form of auto scaling the services. If a particular service has three replicas and there is a lot of traffic on those nodes, more replicas are not created automatically.
There is also limitation of automatically adding new nodes to the swarm. At the moment the workaround or solution for these limitations is creating our own scripts.
I haven't gotten to that point yet and so far for me all of this is taken care of manually. But if our cloud provider has an API, we can use that along with scripts that monitor the load on all of the nodes and react accordingly.
Final Thoughts
Docker Swarm is an amazingly convenient technology for creating scalable and portable systems. While limitations exist on the platform, they are definitely not show stoppers. I am sure that these limitations will have solutions built into Docker.
I do recommend using Docker for your infrastructure. It will make your entire architecture scalable, and portable. You will be able to move from one cloud provider to another.


